- javascript
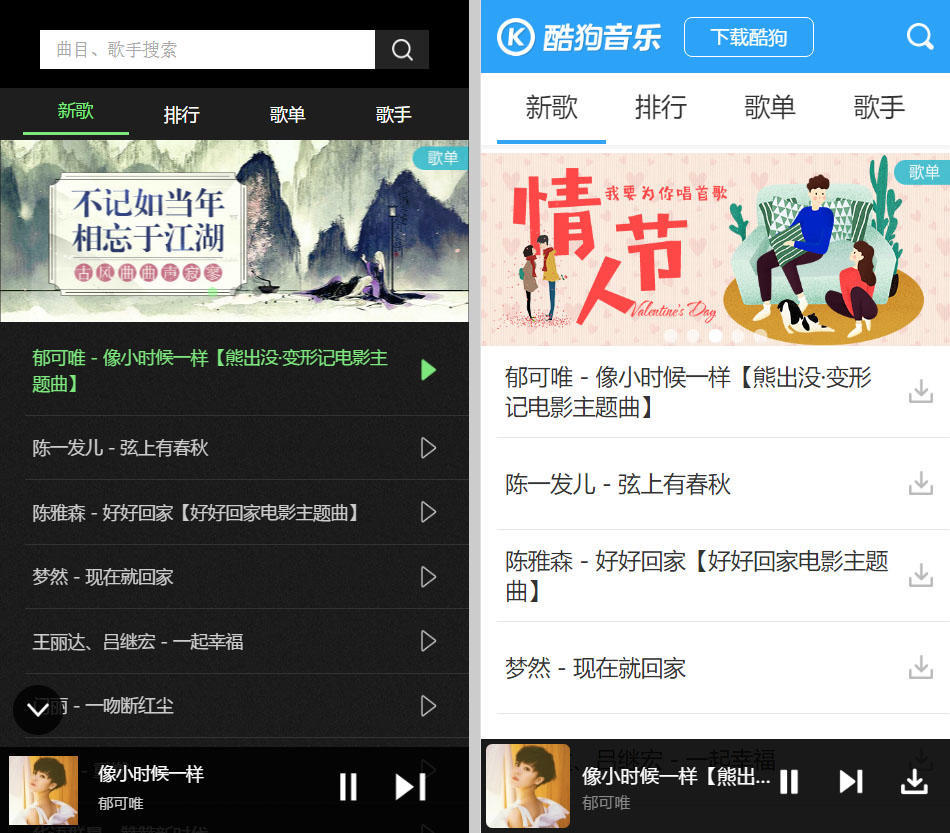
先看一眼效果:
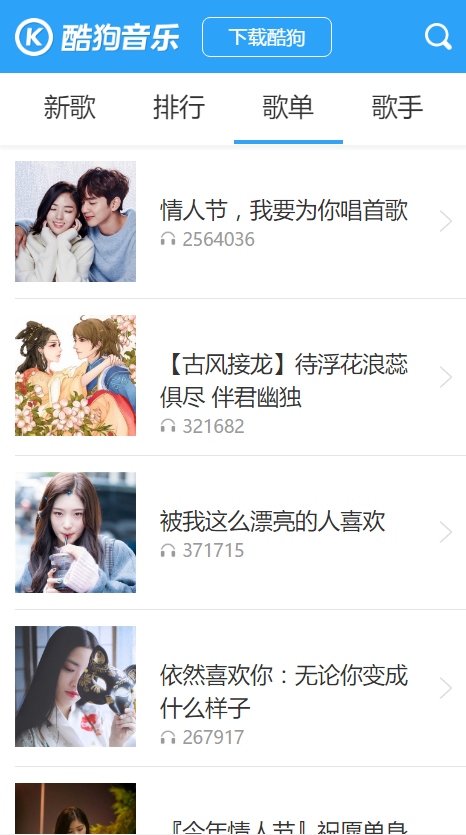
左边的是我写的,右边的是酷狗手机网页,除了换了层皮,是不是赶脚一毛一样?没错,数据全是抓取的,啦啦啦...
原理其实很简单,就是利用ajax直接去请求别人的网页,然后拿到html的文本,从中提取和整理自己所需要的数据。
但是如果你真的直接用ajax去get别人的网页,你会尴尬的发现跨域了...所以需要代理,先用自己的服务器去请求别人的网页,再丢出来......
最简单的代理是用php来做,虚拟主机就能跑起来,只需要几行即可:
<?php
// 允许所有域访问
header("Access-Control-Allow-Origin: *");
// 接收一个参数,参数名叫url
$url = $_GET['url'];
// 获取这个网页的html
$res = file_get_contents($url);
// 输出这个html
echo $res;
?>如果你暂时搞不定代理,我这里提供一个get的代理接口:
http://www.xi-g.com:4000/agent_api
参数名是url,参数内容必须是http打头,例如:
http://www.xi-g.com:4000/agent_api?url=http://m.kugou.com
点这个连接,就会打开 http://m.kugou.com 这个网页的内容
有了代理之后,接下来我们来发起ajax请求:
// 调个ajax
$.ajax({
type:'get',
url: 'http://www.xi-g.com:4000/agent_api?url=http://m.kugou.com',
success: function(data) {
// 打印看看是个什么玩意
console.log(data);
}
});打印结果:
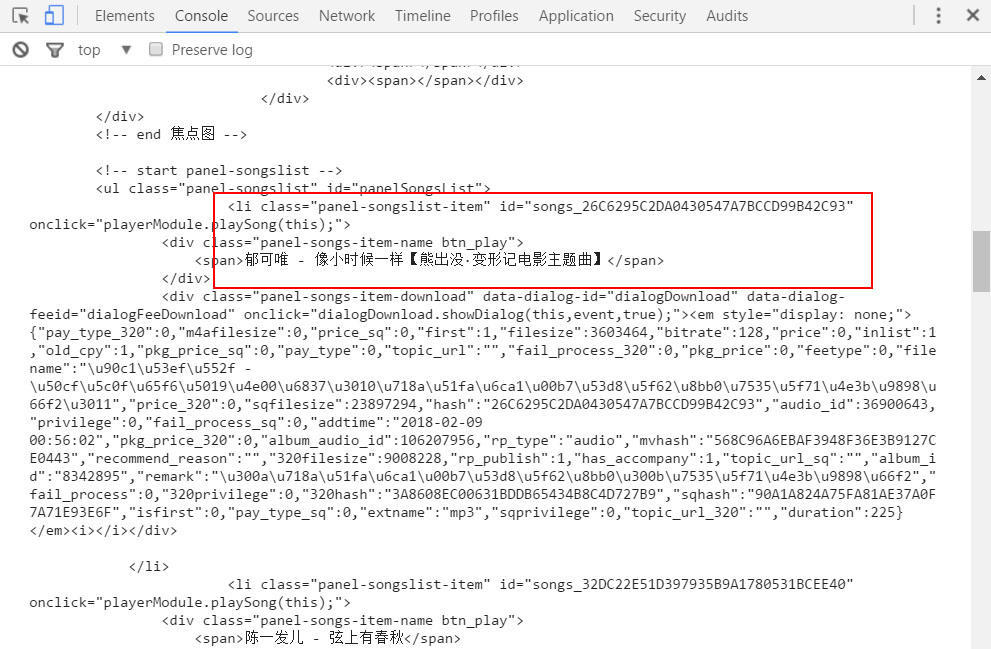
我们已经把整个酷狗首页的html字符串拿到了,接下来是重点,怎么提取数据:
$.ajax({
type:'get',
url: 'http://www.xi-g.com:4000/agent_api?url=http://m.kugou.com',
success: function(data) {
// 创建一个div的盒子存起来
var div = document.createElement('div');
// 把整个html的字符串存到这个div节点里
div.innerHTML = data;
// 分析html结构后,把类名为.panel-songslist-item的元素全部存到list变量里
// querySelectorAll()以数组形式返回所有匹配节点
var list = div.querySelectorAll('.panel-songslist-item');
// 定义一个空数组
var songList = [];
// 遍历list提取歌单数据,整理格式
for(var i = 0; i<list.length; i++){
// 定义空对象
var song = {};
// 查找类名为.panel-songs-item-name的元素里的span节点里的文本存到song.title属性
song.title = list[i].querySelector('.panel-songs-item-name span').textContent;
// 取到每个list元素的id值
song.hash = list[i].id.substr(6);
// 把song对象推入songList数组
songList.push(song);
}
// 我们来打印songList这个对象数组看看
console.log(songList);
}
});打印结果:
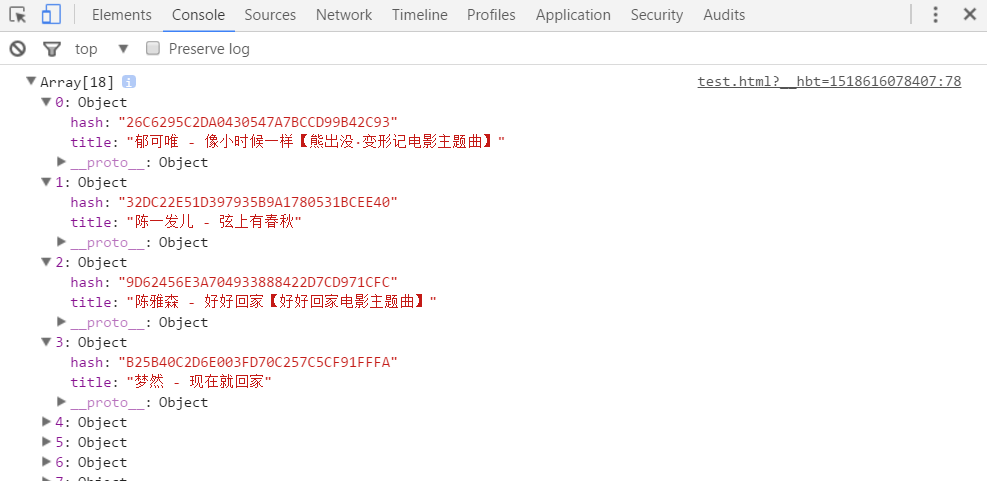
现在我们就把酷狗首页的歌单数据给拿到了,只要拿到数据就能构建我们的页面了,是不是十分神奇,关键点还是对querySelectorAll()和querySelector()这两个方法的运用,根据id名、class名、标签名来查找元素提取数据。
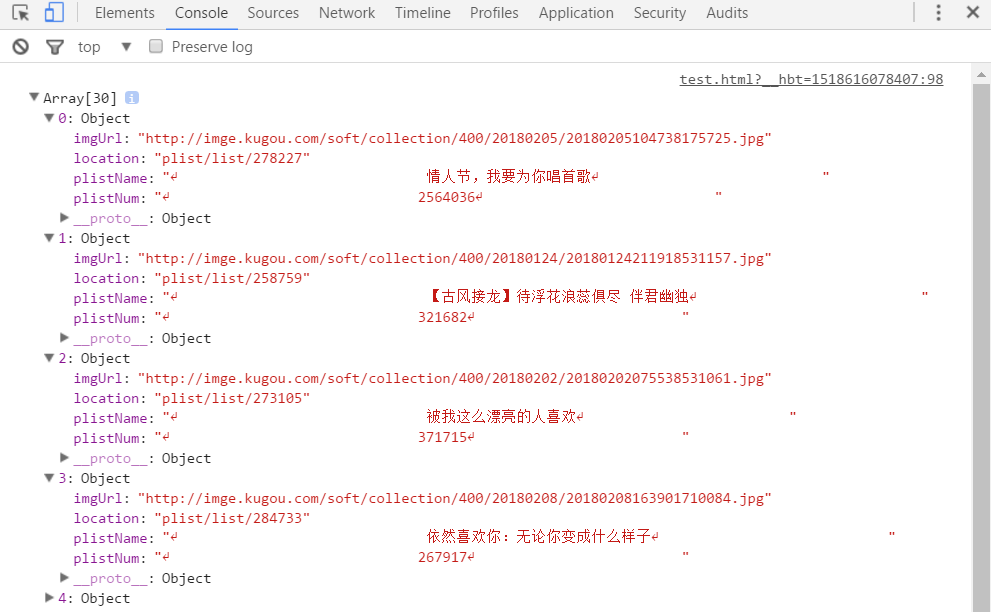
我们再来提取一下歌单页面的数据,还是老方法,但是需要仔细分析页面才能提取到我们想要的数据:
$.ajax({
type:"get",
url: "http://www.xi-g.com:4000/agent_api?url=http://m.kugou.com/plist/index",
success: function(data) {
var div = document.createElement('div');
div.innerHTML = data;
var list = div.querySelectorAll('.panel-img-list li');
var plistList = [];
for(var i = 0; i<list.length; i++){
var plist = {};
plist.imgUrl = list[i].querySelector('.panel-img-left img').getAttribute('_src');
plist.plistName = list[i].querySelector('.panel-img-content-first').textContent;
plist.plistNum = list[i].querySelector('.panel-img-content-sub').textContent;
plist.location = "plist/list/"+list[i].querySelector('a').href.substr(30);
plistList.push(plist);
}
console.log(plistList);
}
});
打印结果:
就是这么简单,小伙伴们学会了没有,赶紧去试着抓取几个新闻页面的数据来玩玩吧~
我给大家推荐一个练习的网站:
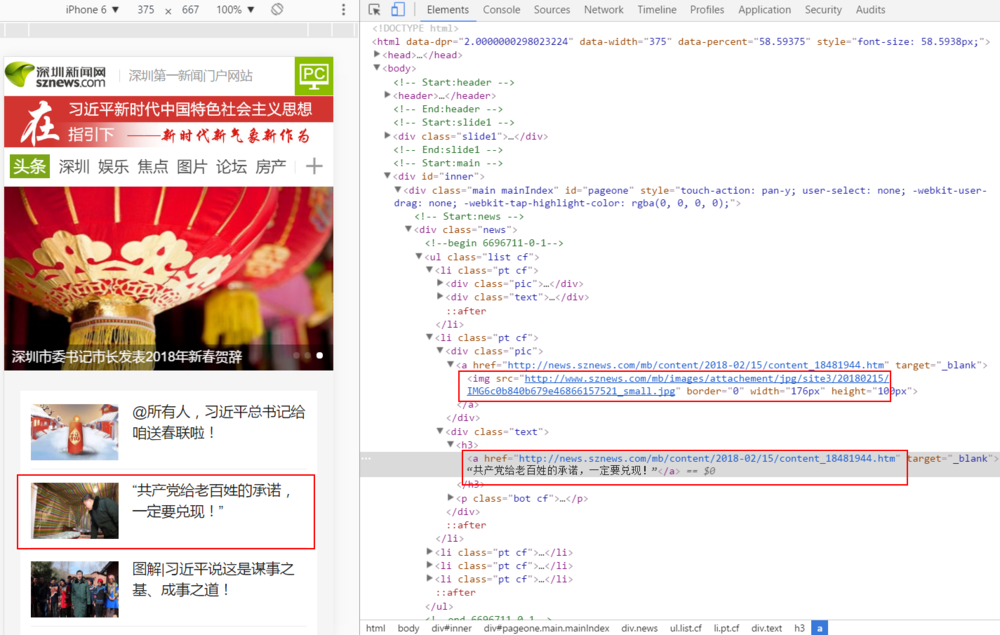
深圳新闻网:http://m.sznews.com/
每一条新闻都是带a标签链接的,根据这个链接我们可以进行二次爬取,即从列表页爬进详情页...